《系统性能调优必知必会》学习笔记,涵盖CPU缓存、内存管理、磁盘I/O、网络性能等核心知识点。
系统性能调优必知必会
作者: 陶辉
CPU缓存
CPU 的多级缓存
比如,Linux系统上,离CPU最近的一级缓存是32KB,二级缓存是256KB,最大的三级缓存则是20MB。
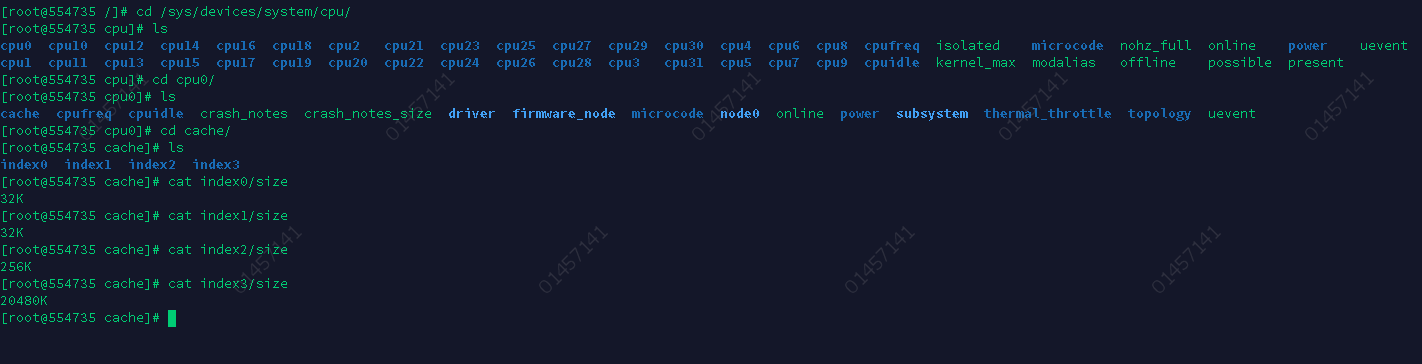
你可能注意到,三级缓存要比一、二级缓存大许多倍,这是因为当下的CPU都是多核心的,每个核心都有自己的一、二级缓存,但三级缓存却是一颗CPU上所有核心共享的。
程序执行时,会先将内存中的数据载入到共享的三级缓存中,再进入每颗核心独有的二级缓存,最后进入最快的一级缓存,之后才会被CPU使用,就像下面这张图。
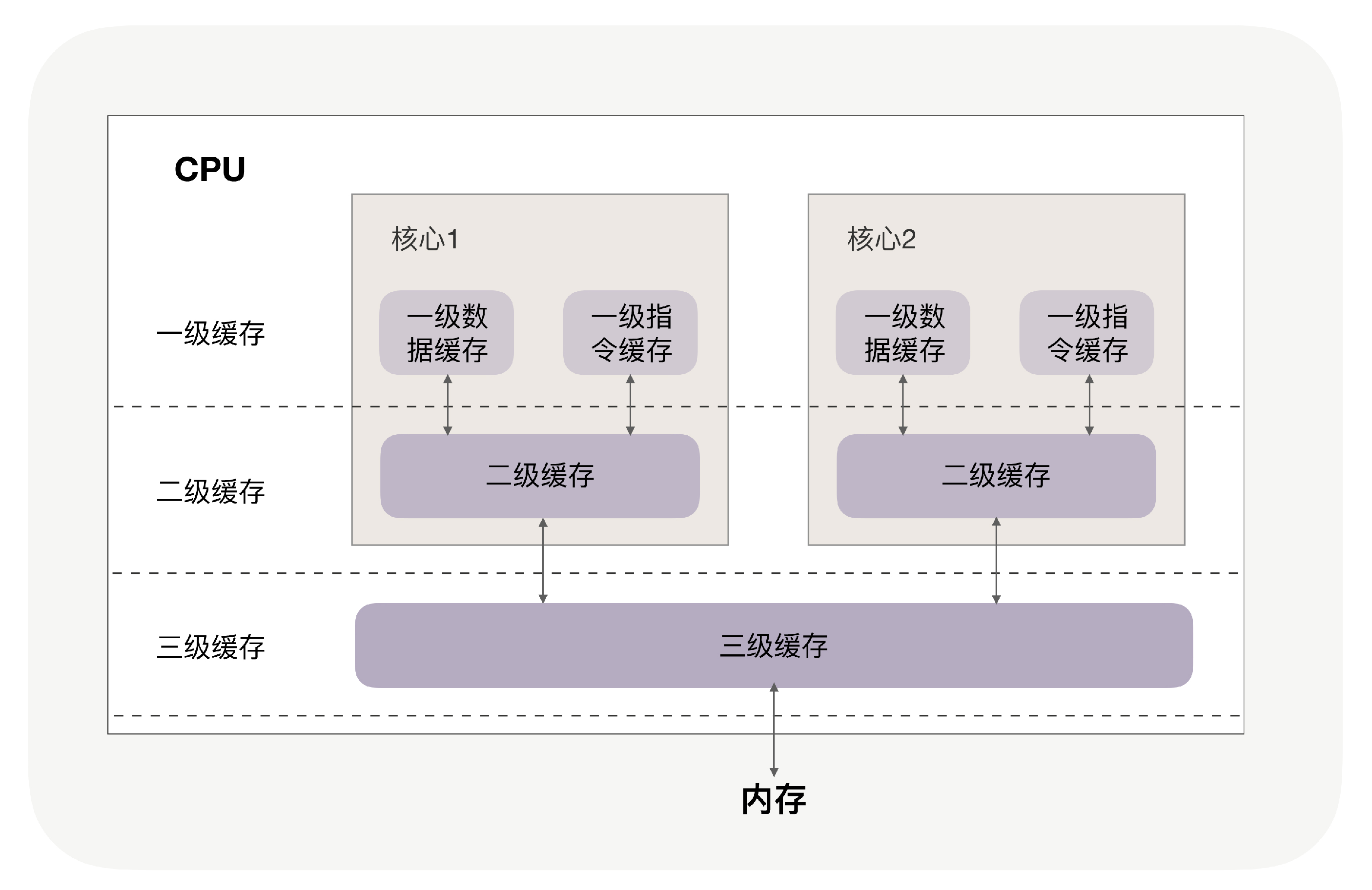
缓存要比内存快很多。CPU访问一次内存通常需要100个时钟周期以上,而访问一级缓存只需要4~5个时钟周期,二级缓存大约12个时钟周期,三级缓存大约30个时钟周期(对于2GHZ主频的CPU来说,一个时钟周期是0.5纳秒。
如果CPU所要操作的数据在缓存中,则直接读取,这称为缓存命中。命中缓存会带来很大的性能提升,因此,我们的代码优化目标是提升 CPU 缓存的命中率。
当然,缓存命中率是很笼统的,具体优化时还得一分为二。比如,你在查看CPU缓存时会发现有2个一级缓存(比如Linux上就是上图中的index0 和 index1),这是因为,CPU会区别对待指令与数据。比如,“1+1=2”这个运算,“+”就是指令,会放在一级指令缓存中,而“1”这个输入数字,则放在一级数据缓存中。虽然在冯诺依曼计算机体系结构中,代码指令与数据是放在一起的,但执行时却是分开进入指令缓存与数据缓存的,因此我们要分开来看二者的缓存命中率。
提升数据缓存的命中率
缓存一次性会载入多少元素呢?CPU Cache Line相关,它定义了缓存一次载入数据的大小,Linux上你可以通过coherency_line_size配置查看它,通常是64字节。

遇到这种遍历访问数组的情况时,按照内存布局顺序访问将会带来很大的性能提升。
关于CPU Cache Line的应用其实非常广泛,如果你用 Nginx,会发现它是用哈希表来存放域名、HTTP头部等数据的,这样访问速度非常快,而哈希表里桶的大小如server_names_hash_bucket_size,它默认就等于 CPU Cache Line 的值。由于所存放的字符串长度不能大于桶的大小,所以当需要存放更长的字符串时,就需要修改桶大小,但Nginx 官网上明确建议它应该是CPU Cache Line的整数倍。
为什么要做这样的要求呢?就是因为缓存是按照64字节的整数倍来访问内存的,哈希表的桶按此大小排列布局,就可以尽量减少访问内存的次数。比如,若桶大小为64字节,那么根据地址获取字符串时只需要访问一次内存,而桶大小为50字节,会导致最坏2次访问内存,而70字节最坏会有3次访问内存。
提升指令缓存的命中率
当代码中出现if、switch等语句时,意味着此时至少可以选择跳转到两段不同的指令去执行。如果分支预测器可以预测接下来要在哪段代码执行(比如 if 还是 else 中的指令),就可以提前把这些指令放在缓存中,CPU执行时就会很快。当数组中的元素完全随机时,分支预测器无法有效工作,而当array数组有序时,分支预测器会动态地根据历史命中数据对未来进行预测,命中率就会非常高。
提升多核 CPU 下的缓存命中率
操作系统提供了将进程或者线程绑定到某一颗CPU上运行的能力。如Linux上提供了sched_setaffinity方法实现这一功能。
Perf工具也提供了cpu-migrations事件,它可以显示进程从不同的CPU核心上迁移的次数。
如果你在用Linux操作系统,可以通过一个名叫Perf的工具直观地验证缓存命中的情况(可以用yum install perf或者apt-get install perf安装这个工具)。
执行perf stat可以统计出进程运行时的系统信息(通过-e选项指定要统计的事件,如果要查看三级缓存总的命中率,可以指定缓存未命中 cache-misses 事件,以及读取缓存次数cache-references事件,两者相除就是缓存的未命中率,用1相减就是命中率。类似的,通过L1-dcache-load-misses和L1-dcache-loads可以得到L1缓存的命中率)。
内存池:如何提升内存分配的效率?
在Linux系统中,用Xmx设置JVM的最大堆内存为8GB,但在近百个并发线程下,观察到Java进程占用了14GB的内存。为什么会这样呢?
这是因为,绝大部分高级语言都是用C语言编写的,包括Java,申请内存必须经过C库,而C库通过预分配更大的空间作为内存池,来加快后续申请内存的速度。这样,预分配的6GB的C库内存池就与JVM中预分配的8G内存池叠加在一起,造成了Java进程的内存占用超出了预期。
隐藏的内存池
实际上,在你的业务代码与系统内核间,往往有两层内存池容易被忽略,尤其是其中的C库内存池。
当代码申请内存时,首先会到达应用层内存池,如果应用层内存池有足够的可用内存,就会直接返回给业务代码,否则,它会向更底层的C库内存池申请内存。比如,如果你在Apache、Nginx 等服务之上做模块开发,这些服务中就有独立的内存池。当然,Java中也有内存池,当通过启动参数Xmx指定JVM的堆内存为8GB时,就设定了JVM堆内存池的大小。
你可能听说过Google的TCMalloc和FaceBook的JEMalloc,它们也是C库内存池。当C库内存池无法满足内存申请时,才会向操作系统内核申请分配内存。如下图所示:
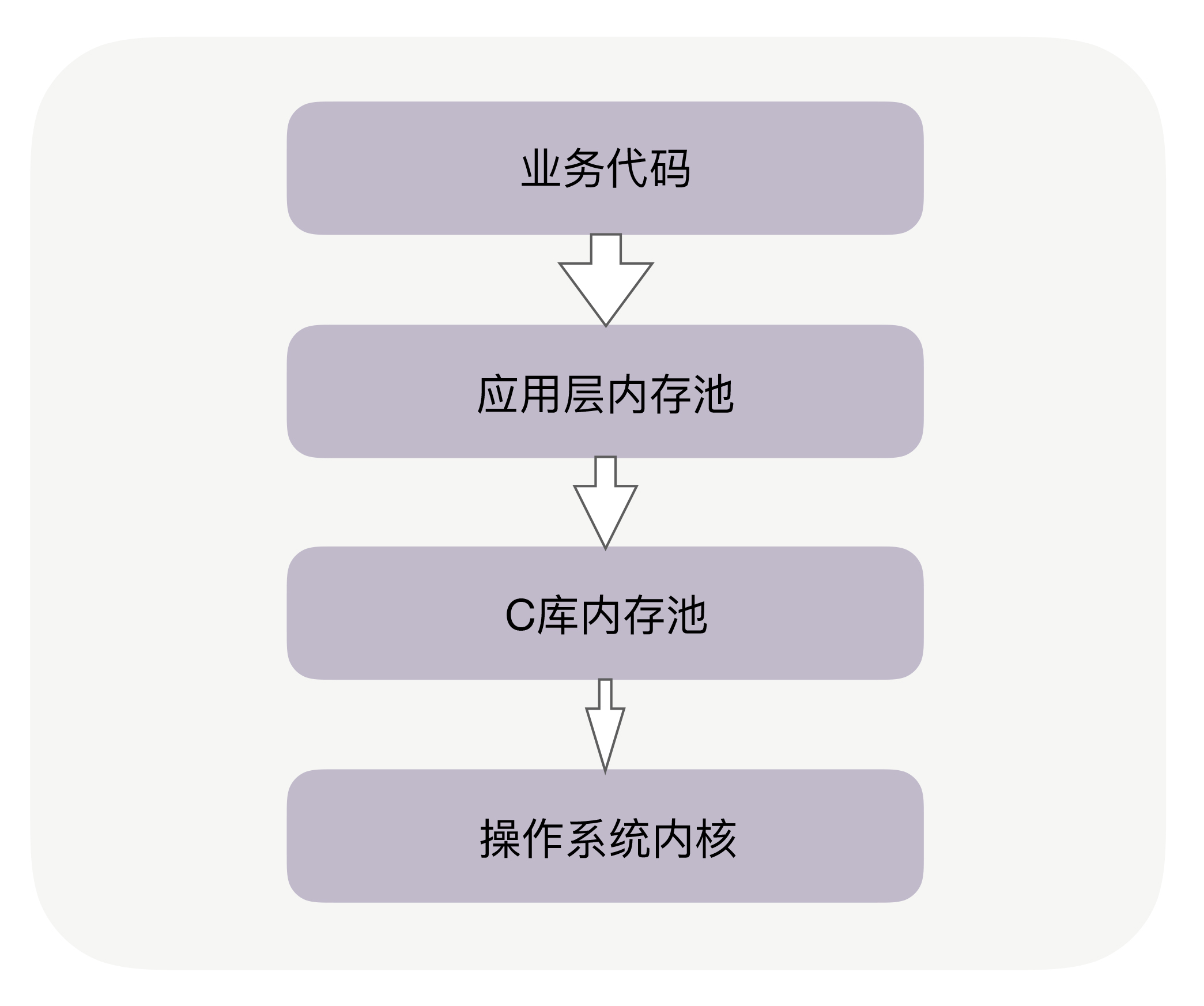
回到文章开头的问题,Java已经有了应用层内存池,为什么还会受到C库内存池的影响呢?这是因为,除了JVM负责管理的堆内存外,Java还拥有一些堆外内存,由于它不使用JVM的垃圾回收机制,所以更稳定、持久,处理IO的速度也更快。这些堆外内存就会由C库内存池负责分配,这是Java受到C库内存池影响的原因。
索引:如何用哈希表管理亿级对象?
内存结构与序列化方案
事实上对于动态(元素是变化的)哈希表,我们无法避免哈希冲突。有两种方法解决哈希冲突:
- 链接法,落到数组同一个位置中的多个数据,通过链表串在一起。使用哈希函数查找到这个位置后,再使用链表遍历的方式查找数据。Java标准库中的哈希表就使用链接法解决冲突。
- 开放寻址法,插入时若发现对应的位置已经占用,或者查询时发现该位置上的数据与查询关键字不同,开放寻址法会按既定规则变换哈希函数(例如哈希函数设为 H(key,i),顺序地把参数i加1),计算出下一个数组下标,继续在哈希表中探查正确的位置。
我们该选择哪种方法呢?
链接法虽然实现简单,还允许存放元素个数大于数组的大小(也叫装载因子大于1),但链接法序列化数据的代价很大,因为使用了指针后,内存是不连续的。
开放寻址法确保所有对象都在数组里,就可以把数组用到的这段连续内存原地映射到文件中(参考Linux中的mmap,Java等语言都有类似的封装),再通过备份文件的方式备份哈希表。虽然操作系统会自动同步内存中变更的数据至文件,但备份前还是需要主动刷新内存
(参考Linux中的msync,它可以按地址及长度来分段刷新,以减少msync的耗时),以确定备份数据的精确时间点。而新的进程启动时,可以通过映射磁盘中的文件到内存,快速重建哈希表提供服务。
使用哈希表,你要注意几个关键问题。
- 生产环境一定要考虑容灾,而把哈希表原地序列化为文件是一个解决方案,它能保证新进程快速恢复哈希表。解决哈希冲突有链接法和开放寻址法,而后者更擅长序列化数据,因此成为我们的首选。
- 亿级数据下,我们必须注重内存的节约使用。数亿条数据会放大节约下的点滴内存,再把它们用于提升哈希数组的大小,就可以通过降低装载因子来减少哈希冲突,提升速度。
- 优化哈希函数也是降低哈希冲突的重要手段,我们需要研究关键字的特征与分布,设计出快速、使关键字均匀分布的哈希函数。
零拷贝:如何高效地传输文件?
协程:如何快速地实现高并发服务?
事实上,无论基于多进程还是多线程,都难以实现高并发,这由两个原因所致。
首先,单个线程消耗的内存过多,比如,64位的Linux为每个线程的栈分配了8MB的内存,还预分配了64MB的内存作为堆内存池。所以,我们没有足够的内存去开启几万个线程实现并发。
其次,切换请求是内核通过切换线程实现的,什么时候会切换线程呢?不只时间片用尽,当调用阻塞方法时,内核为了让CPU充分工作,也会切换到其他线程执行。一次上下文切换的成本在几十纳秒到几微秒间,当线程繁忙且数量众多时,这些切换会消耗绝大部分的CPU运算能力。
实际上,用户态的代码切换协程,与内核切换线程的原理是一样的。内核通过管理CPU的寄存器来切换线程,我们以最重要的栈寄存器和指令寄存器为例,看看协程切换时如何切换程序指令与内存。
每个线程有独立的栈,而栈既保留了变量的值,也保留了函数的调用关系、参数和返回值,CPU中的栈寄存器SP指向了当前线程的栈,而指令寄存器IP保存着下一条要执行的指令地址。因此,从线程1切换到线程2时,首先要把SP、IP 寄存器的值为线程1保存下来,再从内存中找出线程2上一次切换前保存好的寄存器值,写入CPU的寄存器,这样就完成了线程切换。(其他寄存器也需要管理、替换,原理与此相同,不再赘述。)
协程的切换与此相同,只是把内核的工作转移到协程框架实现而已,下图是协程切换前的状态:
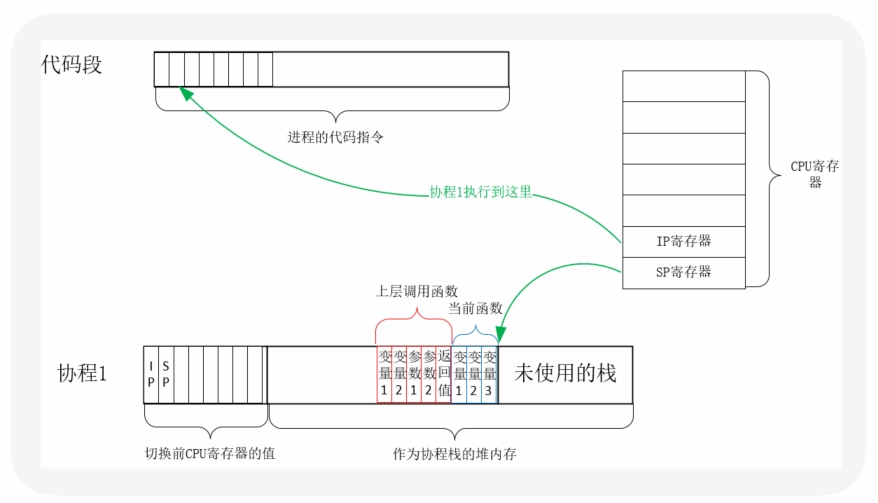
从协程1切换到协程2后的状态如下图所示:
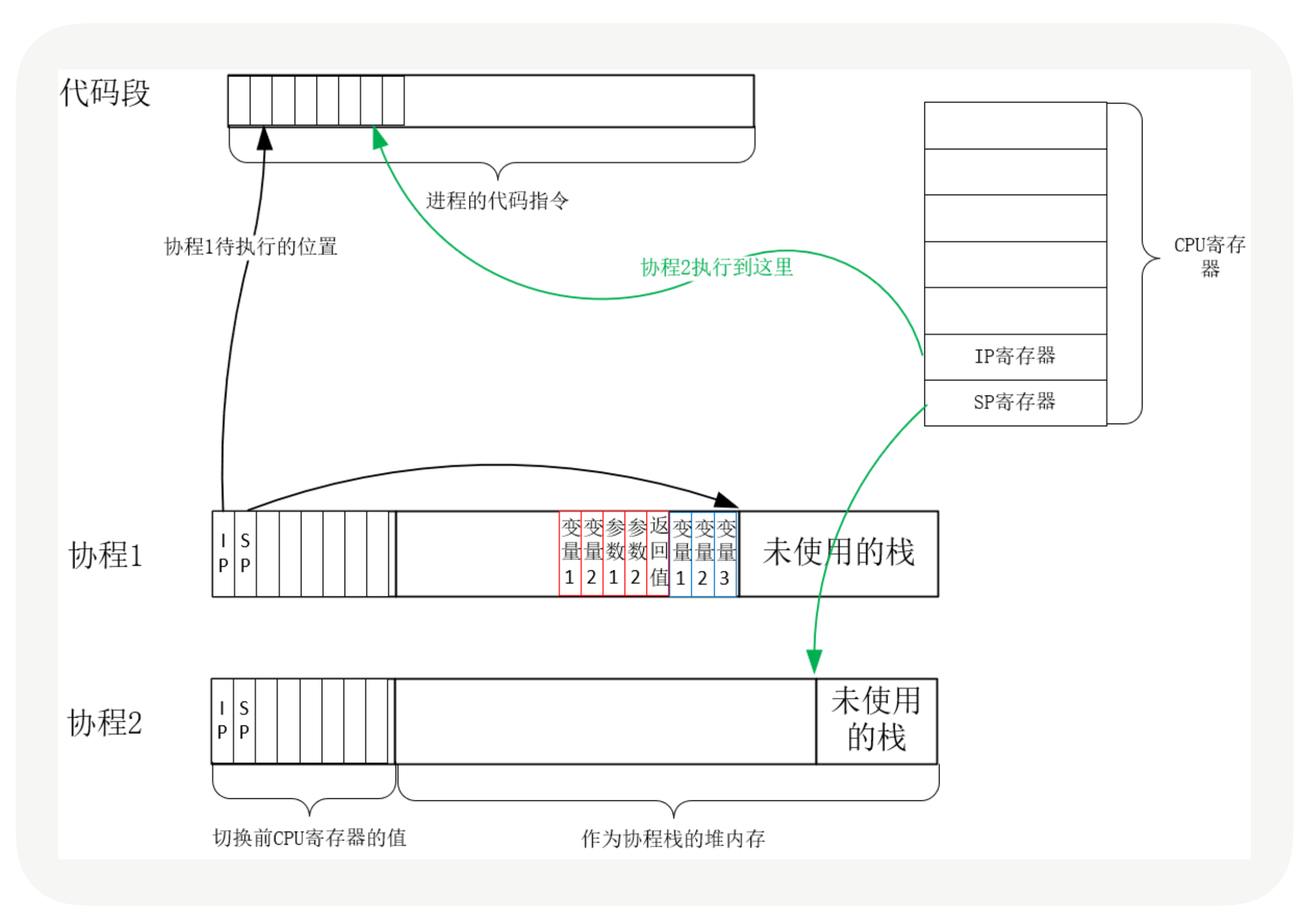
创建协程时,会从进程的堆中分配一段内存作为协程的栈。线程的栈有8MB,而协程栈的大小通常只有几十KB。而且,C库内存池也不会为协程预分配内存,它感知不到协程的存在。这样,更低的内存占用空间为高并发提供了保证,毕竟十万并发请求,就意味着10万个协程。当然,栈缩小后,就尽量不要使用递归函数,也不能在栈中申请过多的内存,这是实现高并发必须付出的代价。
由此可见,协程就是用户态的线程。然而,为了保证所有切换都在用户态进行,协程必须重新封装所有的阻塞系统调用,否则,一旦协程触发了线程切换,会导致这个线程进入休眠状态,进而其上的所有协程都得不到执行。比如,普通的sleep函数会让当前线程休眠,由内核来唤醒线程,而协程化改造后,sleep只会让当前协程休眠,由协程框架在指定时间后唤醒协程。再比如,线程间的互斥锁是使用信号量实现的,而信号量也会导致线程休眠,协程化改造互斥锁后,同样由框架来协调、同步各协程的执行。
所以,协程的高性能,建立在切换必须由用户态代码完成之上,这要求协程生态是完整的,要尽量覆盖常见的组件。
锁:如何根据业务场景选择合适的锁?
互斥锁与自旋锁:休眠还是“忙等待”?
当你无法判断锁住的代码会执行多久时,应该首选互斥锁,互斥锁是一种独占锁。
如果你能确定被锁住的代码执行时间很短,就应该用自旋锁取代互斥锁。自旋锁比互斥锁快得多,因为它通过CPU提供的CAS函数(全称Compare And Swap),在用户态代码中完成加锁与解锁操作。
我们知道,加锁流程包括2个步骤:第1步查看锁的状态,如果锁是空闲的,第2步将锁设置为当前线程持有。
在没有CAS操作前,多个线程同时执行这2个步骤是会出错的。比如线程A执行第1步发现锁是空闲的,但它在执行第2步前,线程B也执行了第1步,B也发现锁是空闲的,于是线程A、B会同时认为它们获得了锁。
CAS函数把这2个步骤合并为一条硬件级指令。这样,第1步比较锁状态和第2步锁变量赋值,将变为不可分割的原子指令。于是,设锁为变量lock,整数0表示锁是空闲状态,整数pid表示线程ID,那么CAS(lock, 0, pid) 就表示自旋锁的加锁操作,CAS(lock, pid,0)则表示解锁操作。
多线程竞争锁的时候,加锁失败的线程会“忙等待”,直到它拿到锁。什么叫“忙等待”呢?它并不意味着一直执行CAS函数,生产级的自旋锁在“忙等待”时,会与CPU紧密配合,它通过CPU提供的PAUSE指令,减少循环等待时的耗电量;对于单核CPU,忙等待并没有意义,此时它会主动把线程休眠。
如果你对此感兴趣,可以阅读下面这段生产级的自旋锁,看看它是怎么执行“忙等待”的:
1 | while (true) { |
如果你能够明确区分出读和写两种场景,可以选择读写锁。
用队列把请求锁的线程排队,按照先来后到的顺序加锁即可,当然读线程仍然可以并发,只不过不能插队到写线程之前。Java中的ReentrantReadWriteLock读写锁,就支持这种排队的公平读写锁。
如何提升TCP三次握手的性能?
当客户端通过发送SYN发起握手时,可以通过tcp_syn_retries控制重发次数。当服务器的SYN半连接队列溢出后,SYN报文会丢失从而导致连接建立失败。我们可以通过netstat -s给出的统计结果判断队列长度是否合适,进而通过tcp_max_syn_backlog参数调整队列的长度。服务器回复SYN+ACK报文的重试次数由tcp_synack_retries参数控制,网络稳定时可以调小它。为了应对 SYN 泛洪攻击,应将 tcp_syncookies 参数设置为1,它仅在 SYN 队列满后开启 syncookie 功能,保证连接成功建立。
服务器收到客户端返回的ACK后,会把连接移入accept队列,等待进程调用accept函数取出连接。如果accept队列溢出,默认系统会丢弃 ACK,也可以通过tcp_abort_on_overflow参数用RST通知客户端连接建立失败。如果netstat统计信息显示,大量的ACK被丢弃后,可以通过listen函数的backlog参数和somaxconn系统参数提高队列上限。
TFO技术绕过三次握手,使得HTTP请求减少了1个RTT的时间。Linux下可以通过tcp_fastopen参数开启该功能。
如何提升TCP四次挥手的性能?
我们把先关闭连接的一方叫做主动方,后关闭连接的一方叫做被动方。
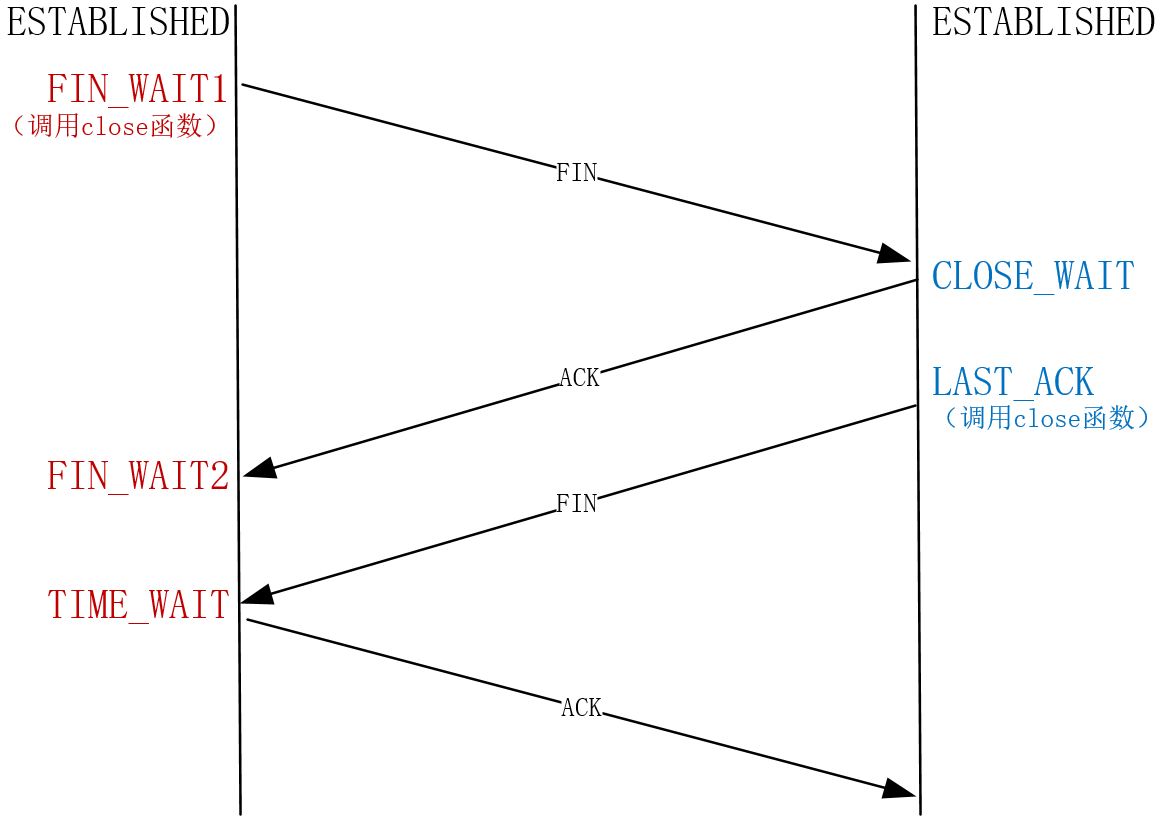
如何修改TCP缓冲区才能兼顾并发数量与传输速度?
如果你在Linux系统中用free命令查看内存占用情况,会发现一栏叫做buff/cache,它是系统内存,似乎与应用进程无关。但每当进程新建一个TCP连接,buff/cache中的内存都会上升4K左右。而且,当连接传输数据时,就远不止增加4K内存了。
这是因为TCP连接是由内核维护的,内核为每个连接建立的内存缓冲区,既要为网络传输服务,也要充当进程与网络间的缓冲桥梁。如果连接的内存配置过小,就无法充分使用网络带宽,TCP传输速度就会很慢;如果连接的内存配置过大,那么服务器内存会很快用尽,新连接就无法建立成功。因此,只有深入理解Linux下TCP内存的用途,才能正确地配置内存大小。
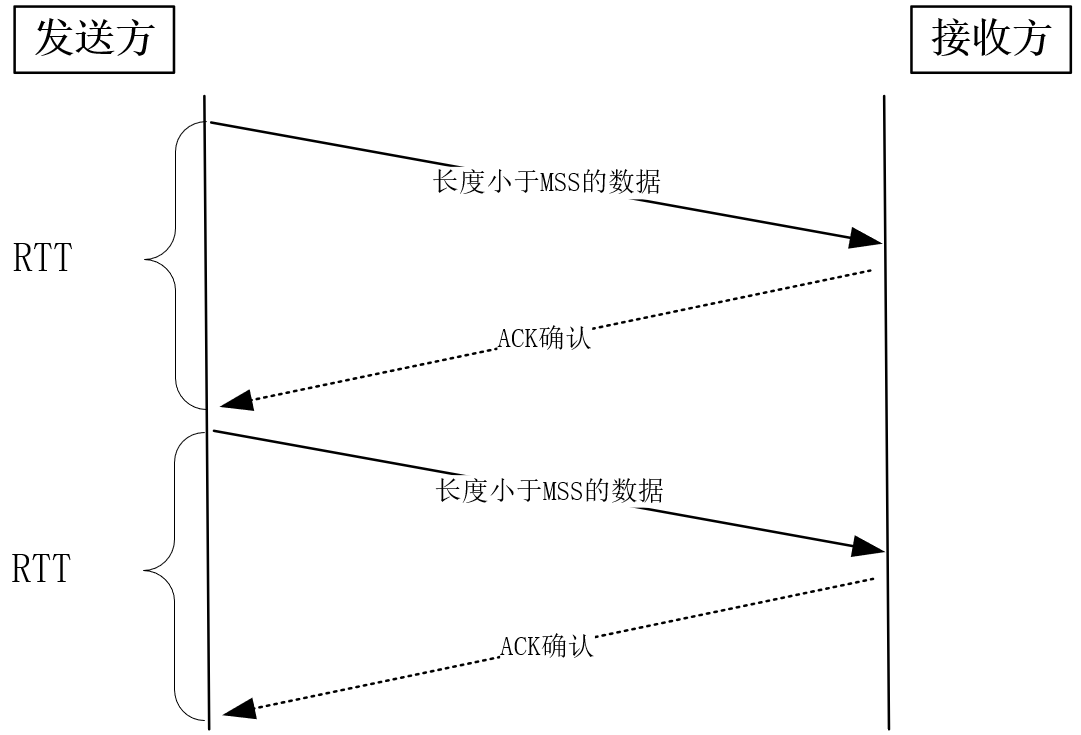
实现高并发服务时,由于必须把大部分内存用在网络传输上,所以除了关注应用内存的使用,还必须关注TCP内核缓冲区的内存使用情况。
TCP使用ACK确认报文实现了可靠性,又依赖滑动窗口既提升了发送速度也兼顾了接收方的处理能力。然而,默认的滑动窗口最大只能到65KB,要想提升发送速度必须提升滑动窗口的上限,在Linux下是通过设置tcp_window_scaling为1做到的。
滑动窗口定义了飞行报文的最大字节数,当它超过带宽时延积时,就会发生丢包。而当它小于带宽时延积时,就无法让TCP的传输速度达到网络允许的最大值。因此,滑动窗口的设计,必须参考带宽时延积。
内核缓冲区决定了滑动窗口的上限,但我们不能通过socket的SO_SNFBUF等选项直接把缓冲区大小设置为带宽时延积,因为TCP不会一直维持在最高速上,过大的缓冲区会减少并发连接数。Linux带来的缓冲区自动调节功能非常有效,我们应当把缓冲区的上限设置为带宽时延积。其中,发送缓冲区的调节功能是自动打开的,而接收缓冲区需要把tcp_moderate_rcvbuf设置为1来开启,其中调节的依据根据tcp_mem而定。
如何调整TCP拥塞控制的性能?
当TCP连接建立成功后,拥塞控制算法就会发生作用,首先进入慢启动阶段。决定连接此时网速的是初始拥塞窗口,Linux上可以通过route ip change命令修改它。通常,在带宽时延积较大的网络中,应当调高初始拥塞窗口。
丢包以及重复的ACK都是明确的拥塞信号,此时,发送方就会调低拥塞窗口减速,同时修正慢启动阈值。这样,将来再次到达这个速度时,就会自动进入拥塞避免阶段,用线性速度代替慢启动阶段的指数速度提升窗口大小。
当然,重复ACK意味着发送方可以提前重发丢失报文,快速重传算法定义了这一行为。同时,为了使得重发报文的过程中,发送速度不至于出现断崖式下降,TCP又定义了快速恢复算法,发送方在报文重新变得有序后,结束快速恢复进入拥塞避免阶段。但以丢包作为网络拥塞的信号往往为时已晚,于是以BBR算法为代表的测量型拥塞控制算法应运而生。当飞行中报文数量不变,而网络时延升高时,就说明网络中的缓冲队列出现了积压,这是进行拥塞控制的最好时机。Linux高版本支持BBR算法,你可以通过tcp_congestion_control配置更改拥塞控制算法。
实战:单机如何实现管理百万主机的心跳服务?
优化TLS=SSL性能该从何下手?
如何提升HTTP-1.1性能?
HTTP-2是怎样提升性能的?
一致性哈希:如何高效地均衡负载?
与程序员相关的SSD性能知识
加餐与分享
留言
鲤鲤鱼:我们集群有一个问题,某一台物理机的CPU会被Hadoop yarn的查询任务打满,并且占用最多的pid在不停的变化,我查看了TIME_WAIT的个数好像也不是很多,在顶峰的时候还没达到一万,能够持续一两个小时。这个问题您有没有什么思路呢?
作者:解决性能问题,一般有两种方法:经验派和“理论”派。前者就是基于自己的经验概率,将能想到的优化方法都试一遍,这种方式通常又有效又快速,但无法解决复杂的问题。而所谓理论派,就是沿着固定的思路,使用二分法,从高至低慢慢下沉到细节。具体到你的问题,我建议你先看看,CPU占用的是用户态还是系统态,用户态的话就要分析代码了,系统态还要进一步分析。火焰图通常是个很好的办法,虽然搭能画火焰图的环境很麻烦,但这种底层方法很有效。
杨文宇:链表的内存地址不连续是如何影响序列化的?老师能具体说一下吗?
作者:当数组外还有链表中的元素时,序列化就必须遍历所有元素,比如,至少要做1次循环,把每1个遍历到的元素的值,序列化写入至另一段内存中。而使用闭散列时,可以直接将这个数组占用的内存作为序列化后的数据。
helloworld:“第二,读取磁盘数据时,需要先找到数据所在的位置,对于机械磁盘来说,就是旋转磁头到数据所在的扇区,再开始顺序读取数据。其中,旋转磁头耗时很长,为了降低它的影响,PageCache使用了预读功能。”那是不是使用SSD这类固态硬盘(不用旋转磁头),PageCache就没有很大的影响?
作者:对的!其实,当下的操作系统对SSD磁盘的支持还不够,当SSD广泛应用时,文件系统还需要跟上,得获得很大的性能提升才可以。
Robust:“然而,共享地址空间虽然可以方便地共享对象,但这也导致一个问题,那就是任何一个线程出错时,进程中的所有线程会跟着一起崩溃。”这里的出错应该表示一些特殊的错误吧,或者是说和共享内存有关的错误,比如申请不到内存等。老师,我理解得没错吧?
作者:这里指无法恢复的错误,不仅是内存申请错误,比如访问已经释放的资源,且没有捕获异常或者无法捕获异常,进而操作系统只能杀死线程时,进程里的其它线程也会被杀死。
范闲:用户态的协程不能用互斥或者自旋,会进入内核态与其设计初衷相悖,Python里面用的yield。
作者:是的,用户态协程需要用户态的代码将锁重新实现一遍,其中实现时不能用到内核提供的系统调用。
Geek_007:看评论区,很多同学都说是长连接,普通的HTTP keep-alive会不会有坑,三大运营商或者中间网络设备都会将超过一定时间的链接drop掉。如果没有H2这种ping保活的机制,有可能客户端长链接莫名其妙的就被drop掉,客户端只能依赖超时来感知异常,反倒是影响性能了。
作者:是的,不只网络设备,一些代理服务器为了减轻自己的负担,也会把长连接断掉,比如Nginx默认关闭75秒没有数据交互的keep-alive长连接。
大咖助场
场景1:失败引发轮询
案例
在使用Apache HttpClient发送HTTP请求时,稍有经验的程序员都知道去控制下超时时间,这样,在连接不上服务器或者服务器无响应时,响应延时都会得到有效的控制,例如我们会使用下面的代码来配置HttpClient:
1 | RequestConfig requestConfig = RequestConfig.custom(). |
以上面的代码为例,你能估算出响应时间最大是多少么?上面的代码实际设置了三个参数,是否直接相加就能计算出最大延时时间?即所有请求100%控制在6秒。
先不说结论,通过实际的生产线观察,我们确实发现大多符合我们的预期:可以说99.9%的响应都控制在6秒以内,但是总有一些“某年某月某天”,发现有一些零星的请求甚至超过了10秒,这又是为什么?
解析
经过问题跟踪,我们发现我们访问的URL是一个下游服务的域名(大多如此,并不稀奇),而这个域名本身有点特殊,由于负载均衡等因素的考虑,我们将它绑定到了多个IP地址。所以假设这些IP地址中,一些IP地址指向的服务临时不服务时,则会引发轮询,即轮询其它IP地址直到最终成功或失败,而每一次轮询中的失败都会额外增加一倍ConnectTimeout,所以我们发现超过6秒甚至10秒的请求也不稀奇了。我们可以通过HttpClient的源码来验证下这个逻辑(参考org.apache.http.impl.conn.DefaultHttpClientConnectionOperator.connect方法):
1 | public void connect( final ManagedHttpClientConnection conn, final HttpHost host, final InetSocketAddress localAddress, final int connectTimeout, final SocketConfig socketConfig, final HttpContext context) throws IOException { |
通过以上代码,我们可以清晰地看出:在一个域名能解析出多个IP地址的场景下,如果其中部分IP指向的服务不可达时,延时就可能会增加。这里不妨再举个例子,对于Redis集群,我们会在客户端配置多个连接节点(例如在SpringBoot中配置spring.redis.cluster.nodes=10.224.56.101:8001,10.224.56.102:8001),通过连接节点来获取整个集群的信息(其它所有节点)。正常情况下,我们都会连接成功,所以我们没有看到长延时情况,但是假设刚初始化时,连接的部分节点不服务了,那这个时候就会连接其它配置的节点,从而导致延时倍增。
场景2:STW
假设某天我们看到零星请求有“掉队”,且没有什么规律,但是又持续发生,我们往往都会怀疑是网络抖动,但是假设我们的组件是部署在同一个网络内,实际上,不大可能是网络原因导致的,而更可能是GC的原因。当然,跟踪GC有N多方法,这里我只是额外贴上了组件B使用的跟踪代码:
1 | List<GarbageCollectorMXBean> gcbeans = ManagementFactory.getGarbageCollectorMX; |
另外同样是停顿,发生的时机不同,呈现的效果也不完全相同,具体问题还得具体分析。至于应对这个问题的策略,就是我们写Java程序一直努力的方向:减少GC引发的STW时间。
场景3:网络抖动
解析
那什么是网络抖动呢?网络抖动是衡量网络服务质量的一个指标。假设我们的网络最大延迟为100ms,最小延迟为10ms,那么网络抖动就是90ms,即网络延时的最大值与最小值的差值。差值越小,意味着抖动越小,网络越稳定。反之,当网络不稳定时,抖动就会越大,网络延时差距也就越大,反映到上层应用自然是响应速度的“掉队”。
为什么网络抖动如此难以避免?这是因为网络的延迟包括两个方面:传输延时和处理延时。忽略处理延时这个因素,假设我们的一个主机进行一次服务调用,需要跨越千山万水才能到达服务器,我们中间出“岔子”的情况就会越多。我们在Linux下面可以使用traceroute命令来查看我们跋山涉水的情况,例如从我的Linux机器到百度的情况是这样的:
1 | jiankunking@kube-node-1:~# traceroute www.baidu.com |
*是指此次trace超时。一般会对每一个route连接3次。
通过上面的命令结果我们可以看出,我的机器到百度需要很多“路”。当然大多数人并不喜欢使用traceroute来评估这段路的艰辛程度,而是直接使用ping来简单看看“路”的远近。例如通过以下结果,我们就可以看出,我们的网络延时达到了40ms,这时网络延时就可能是一个问题了。
1 | jiankunking@kube-node-1:~# ping www.baidu.com |
其实上面这两个工具的使用只是直观反映网络延时,它们都默认了一个潜规则:网络延时越大,网络越抖动。且不说这个规则是否完全正确,至少从结果来看,评估网络抖动并不够直观。
所以我们可以再寻求一些其它的工具。例如可以使用MTR工具,它集合了tractroute和ping。我们可以看下执行结果:下图中的best和wrst字段,即为最好的情况与最坏的情况,两者的差值也能在一定程度上反映出抖动情况,其中不同的host相当于traceroute经过的“路”。
命令:
1 | mtr www.baidu.com |
响应结果:
1 | kube-node-1 (127.0.0.1) 2022-01-27T20:06:22+0800 |

